[ad_1]
This article is part of the AI Decoded series, aimed at making AI technology more comprehensible while highlighting new hardware, software, tools, and enhancements for GeForce RTX PC and NVIDIA RTX workstation users.
Large language models (LLMs) are revolutionizing productivity. These models are capable of drafting documents, summarizing web content, and accurately responding to inquiries on a wide range of topics thanks to extensive training on large datasets.
LLMs are integral to numerous applications within generative AI, such as digital assistants, conversational avatars, and customer service representatives.
Many of today’s advanced LLMs can operate locally on PCs or workstations, offering benefits like enhanced privacy by keeping conversations and content on the device, the ability to use AI without an internet connection, and the powerful performance of NVIDIA GeForce RTX GPUs. Some larger models, however, are too complex to fit into the video memory (VRAM) of local GPUs and necessitate data center hardware.
Nevertheless, it is possible to accelerate parts of a prompt using a data-center-class model on RTX-powered PCs through a method known as GPU offloading. This technique enables users to benefit from GPU acceleration while mitigating GPU memory limitations.
Size and Quality vs. Performance
There exists a balance between the model’s size, the quality of its outputs, and its performance. Generally, larger models provide higher quality responses, albeit at a slower pace, whereas smaller models tend to operate faster but may sacrifice quality.
This balance can be complex; for certain tasks, performance may take precedence over quality. For instance, users involved in content generation might place a greater emphasis on accuracy since it can operate unobtrusively in the background. Conversely, a conversational assistant requires both speedy and precise responses.
The most accurate LLMs, typically designed for data centers, can be tens of gigabytes large, potentially exceeding a GPU’s memory capacity. Traditionally, this would prevent the effective use of GPU acceleration for these models.
GPU offloading, however, permits the use of aspects of the LLM on the GPU while processing others on the CPU, thus enabling optimal GPU acceleration regardless of the model’s size.
Optimize AI Acceleration With GPU Offloading and LM Studio
LM Studio is an application allowing users to download and host LLMs on their desktop or laptop computers. Its user-friendly interface facilitates extensive customization of model operations. Built upon llama.cpp, it is fully optimized for use with GeForce RTX and NVIDIA RTX GPUs.
Through LM Studio and the GPU offloading technique, users can enhance the performance of locally hosted LLMs, even if the entire model cannot fit into VRAM.
With GPU offloading, LM Studio segments the model into smaller parts, or “subgraphs,” representing layers of the model. These subgraphs are not permanently allocated to the GPU and can be dynamically loaded and unloaded as necessary. Users can determine the extent of layer processing by adjusting the GPU offloading slider in LM Studio.
For illustration, consider utilizing this GPU offloading approach with a substantial model like Gemma 2 27B. The “27B” indicates the model’s parameter count, which helps estimate the memory required for operation.
Using a technique known as 4-bit quantization, which compresses the size of an LLM while maintaining accuracy, each parameter takes up roughly half a byte of memory. Consequently, the model should need around 13.5 billion bytes, or 13.5GB — in addition to some overhead, which typically spans 1-5GB.
To fully accelerate this model on the GPU, a total of 19GB of VRAM is necessary, which is available on the GeForce RTX 4090 desktop GPU. By employing GPU offloading, the model can operate on systems with less powerful GPUs while still benefiting from acceleration.
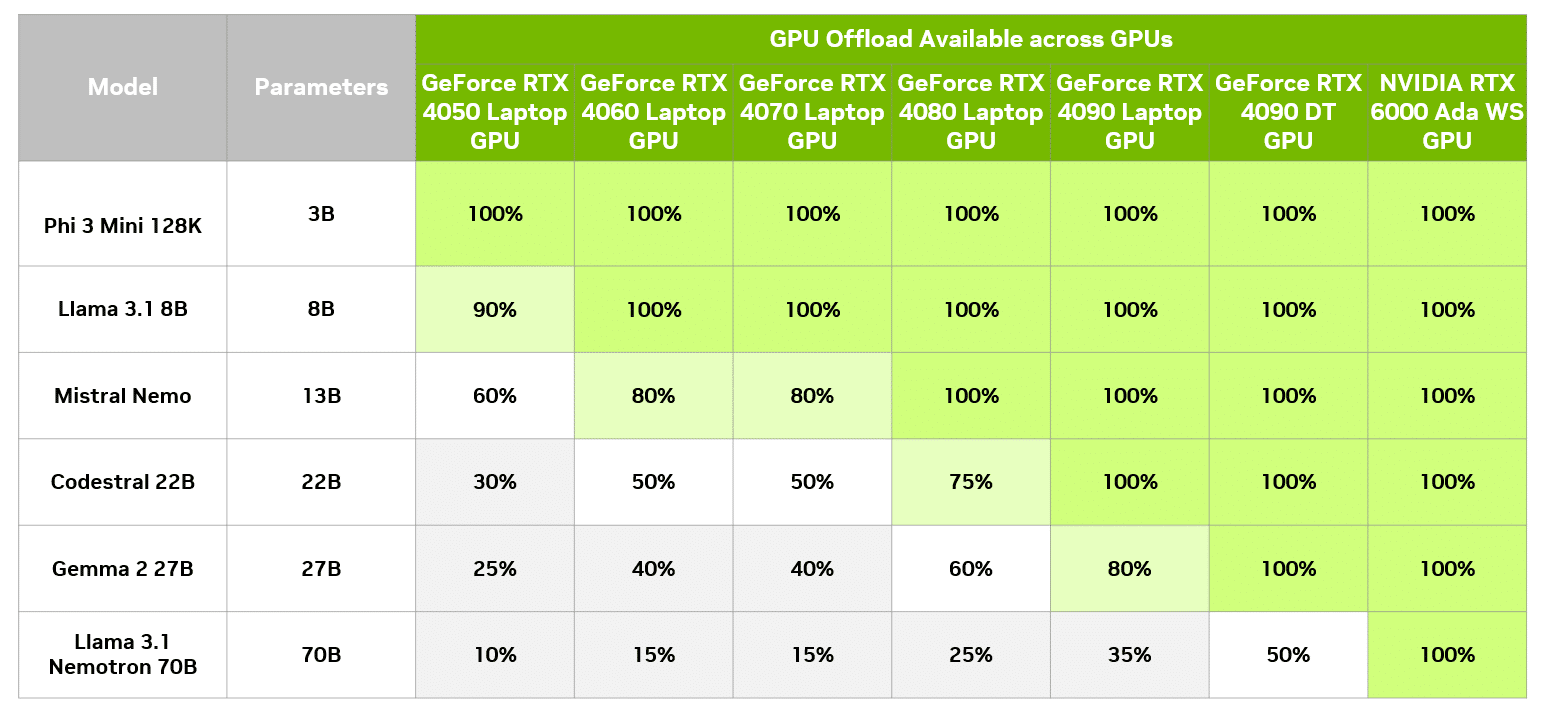
Within LM Studio, users can evaluate the performance effects of different levels of GPU offloading compared to CPU-only processing. The table below showcases the results of executing the same query under varying offloading levels on a GeForce RTX 4090 desktop GPU.

In this particular case, even users with an 8GB GPU can experience substantial performance enhancements compared to CPU-only processing. Naturally, an 8GB GPU can also effectively run a smaller model that fits within GPU memory, thereby achieving full GPU acceleration.
Achieving Optimal Balance
LM Studio’s GPU offloading feature serves as a valuable asset for fully utilizing LLMs designed for data centers, like Gemma 2 27B, on RTX AI PCs. This functionality makes it feasible to access larger and more intricate models across a wide range of GeForce RTX and NVIDIA RTX GPU-equipped PCs.
Download LM Studio to explore GPU offloading with larger models or to experiment with a variety of RTX-accelerated LLMs operating locally on RTX AI PCs and workstations.
Generative AI is revolutionizing gaming, video conferencing, and interactive experiences of all sorts. Stay informed about the latest developments by subscribing to the AI Decoded newsletter.
.
[ad_2]
